High-quality product images are critical for e-commerce sites. Clean backgrounds allow customers to focus on the products and provide a sense of consistency. However, manually removing or replacing backgrounds is an expensive and time-consuming process. Levi9’s data scientist, Simona Stolnicu, automated this process using deep learning image segmentation models. She improved the client’s time for image processing 36.000 times over—from 12 hours to 1.2 seconds for hundreds of images.
Levi9 worked with Wehkamp, a rapidly scaling e-commerce site, to better manage product image background removal. With over half a million daily visitors generating up to 30,000 transactions, Wehkamp processes orders amounting to €3 million in sales each day. Their catalog contains over 400,000 distinct clothing products. Wehkamp adds 10,000 new product listings every month, requiring an efficient system to handle the product images.
Wehkamp used to pay a contracted service up to twelve hours for each batch of several hundred images to be manually edited and prepared. The delivery deadlines were also frequently pushed back. This delay prevented new products from being added to the site promptly, which hampered the rapid iteration that was essential to the business.
Levi9 aimed to reduce the manual post-processing delay by creating its own model to separate products from their photo background. The technical challenge faced by Simona and her colleagues was training an algorithm to generate masks for images in order to delete the background of the apparel photos.

The machine learning project had five phases: data ingestion, data preparation, model training, model deployment, and monitoring.
Data ingestion: Quality is key
The data ingestion phase was focused on developing a robust, accurate dataset. As Simona put it, “The first step in any machine learning project is gathering quality data.”
Levi9 obtained a set of 32,000 product images along with their corresponding human-made masks from Wehkamp’s third-party processing vendor. This “ground truth” data served as the predictive model’s target variable. These pairings between the real image and the binary mask would be used to test various technical solutions, types of algorithms, and finally to find the deep learning solution and train the algorithm.
Data preparation: Clustering for better performance
The data ingestion phase was focused on developing a robust, accurate dataset. As Simona put it, “The first step in any machine learning project is gathering quality data.”
Levi9 spent a significant amount of time and effort preparing the dataset before training could begin. “We went through several stages of work,” Simona Stolnicu explained. “We manually analyzed the images, and then we noticed visually on certain sub-samples that the images are quite different, with far more pants than beach clothes.”
Based on preliminary tests, the team noticed that this variety affected algorithm performance and decided to cluster the images in several categories: long pants; shorts; short-sleeved tops or dresses; long-sleeved tops or dresses; beachwear, sportswear, accessories; and white-color products. All samples were resized to the same dimensions to ensure a consistent image size of 320×320 pixels.
Clustering was done using a semi-automated process that used principal component analysis (PCA) and k-means to group products into visually and stylistically similar categories. Afterwards, the team employed manual verification to polish the groups further.
Some images required augmentation during this stage due to the low contrast between the object of the image and the background. The team tested several augmentation techniques, such as vertically flipping the images or cropping, and performed small initial tests with the algorithm to find the optimal combination between the augmentation techniques and image segmentation.
In total, the team prepared a dataset of 32,000 images grouped into six product clusters. They used approximately 26.000 images for actual model training and 6.000 images for model validation.

Model training: Finding the right architecture and performance metrics
To find the most suitable neural network architecture for the task, Simona did some research on the most popular State of the Art papers in the field. After experimenting with MaskRCNN and BASNet, Levi9’s data scientist found inspiration in a paper published in 2020 that detailed an image segmentation architecture called U^2-Net. “The architecture has a U shape, and in each block, the image is processed again in a U shape. Then each block returns a binary mask prediction, and all of these are aggregated together to obtain the final prediction,” explains Simona.
The U-net architecture proposed in the paper can be trained from the ground up to perform competitively. The innovative architecture enables the network to dig deeper and achieve high resolution while reducing memory and compute costs dramatically.
The core idea of training an image segmentation model relies on providing the algorithm with the original image to let it compute the image mask for background removal and then compare the model output with a human-made, validated image mask.
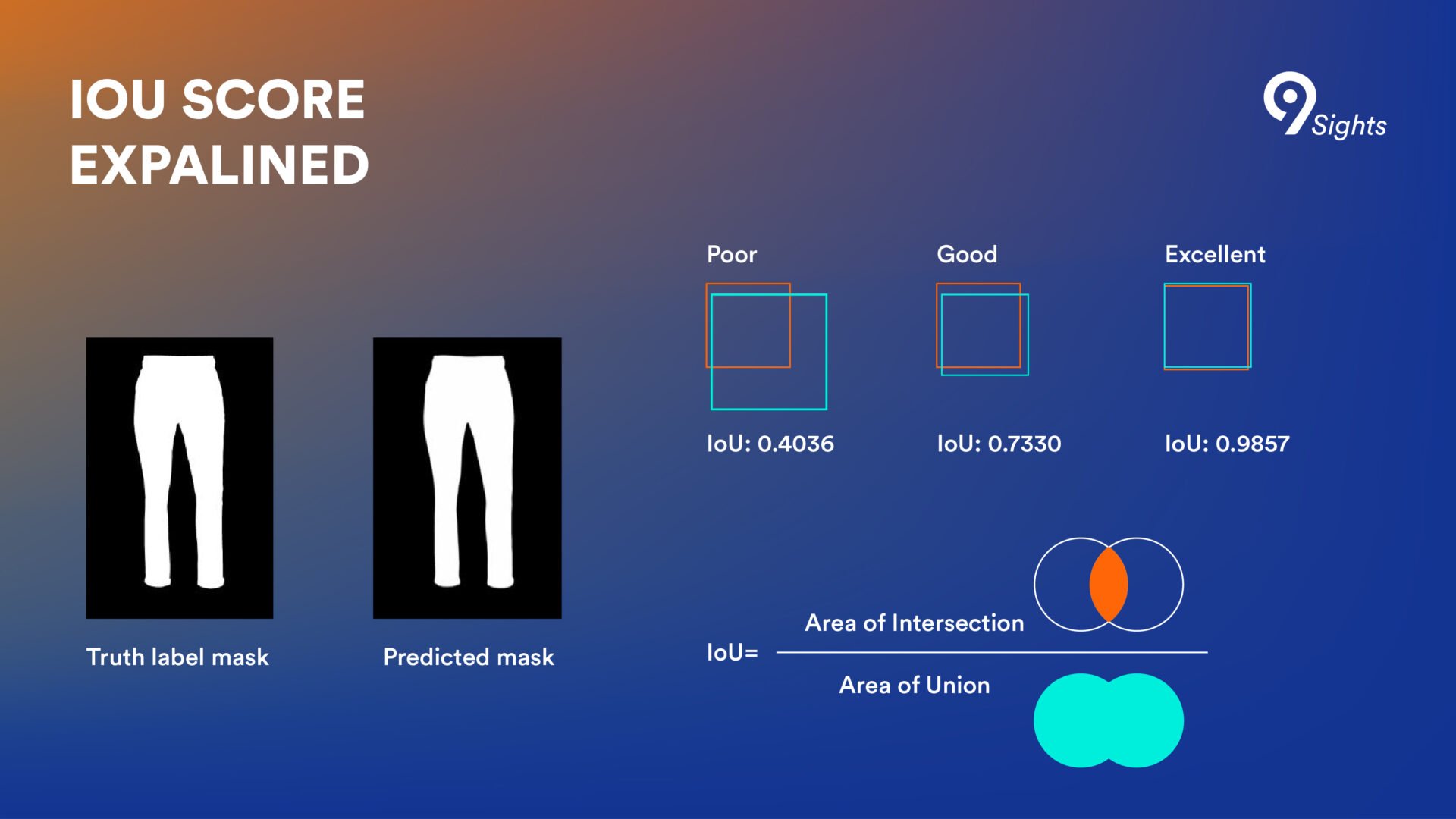
The optimization metric for this comparison is the so-called Intersection over Union (IoU) percent, which measures the similarity percent between the algorithm-generated mask and the real mask. It takes the two masks and calculates the area of the joint images and the area where they intersect. The higher the overlap, the better the IoU score. And the higher the IoU score, the more performant the algorithm is, explains Simona.
The Levi9 team aimed for a score of over 99%. After each round of training, the score would be checked and fed back to the algorithm so that it could adjust its weights for the upcoming training epoch.
The model was taken through 30 such training rounds, or epochs, which took 9 hours. To accelerate the model training, the team split the training data into several batches and used the Horovod library for distributed, parallelized processing across 20 single GPU machines. After each Horovod averages the scores computed on each device after every batch, it automatically adjusts algorithms on each machine.
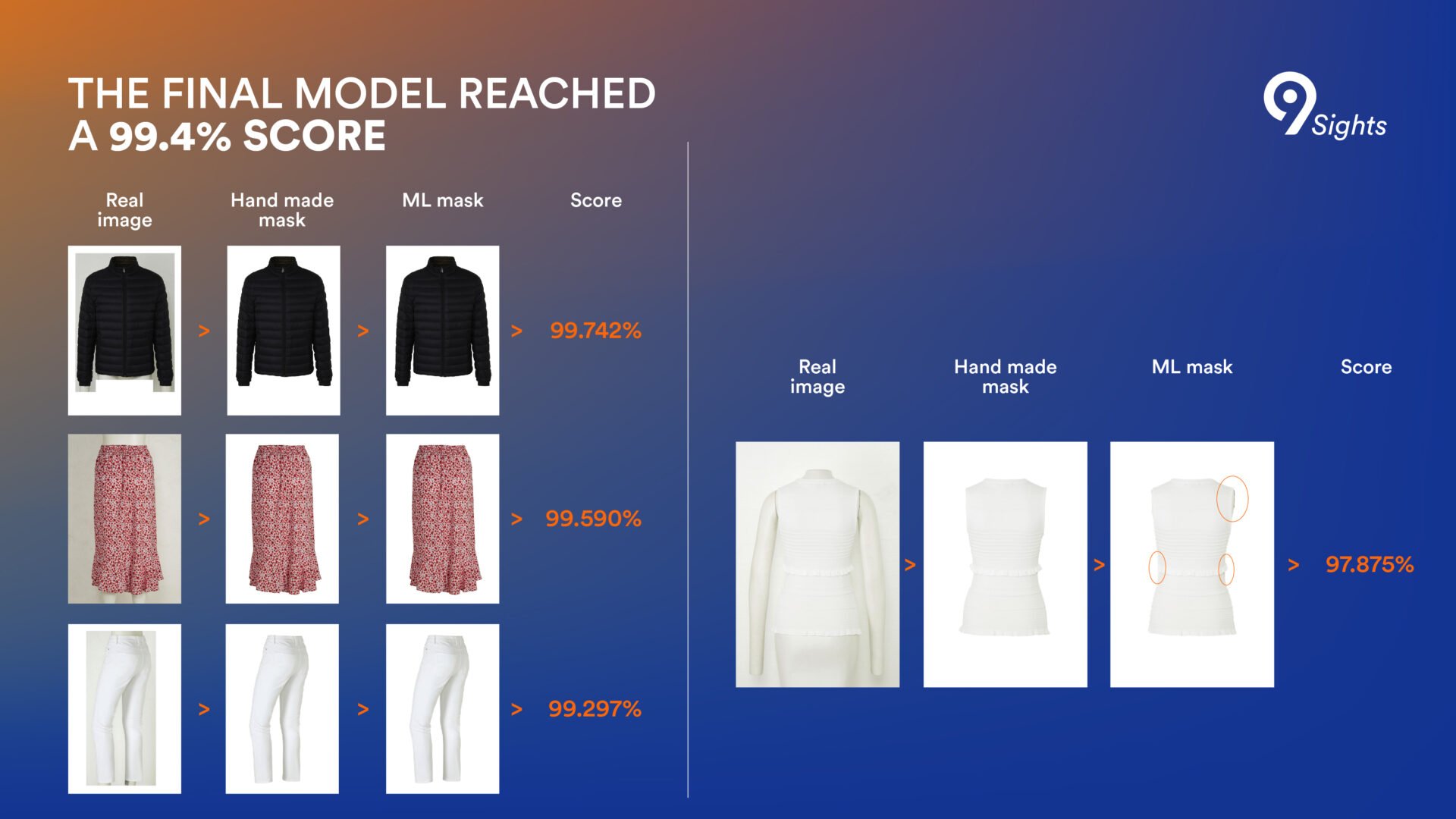
After 24 rounds, the model had already achieved a 99% IoU score, but training continued for six more epochs. The final model reached a 99.4% score, with the highest score for images of shorts and the lowest score for white-colored clothes and beachwear. Careful inspection revealed remaining errors stemming primarily from low-contrast products or thin straps or details.
Deployment: Instant triggers for background removal
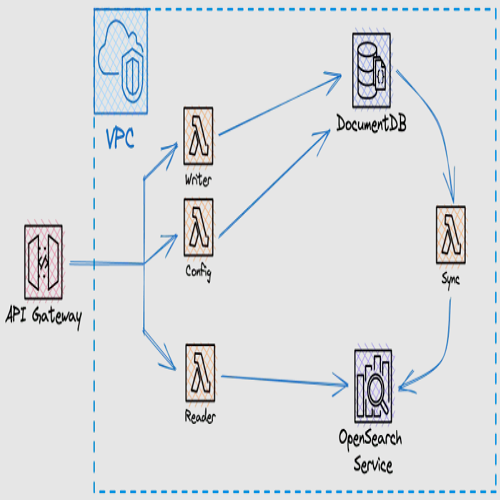
Following successful training, the model was deployed in production using AWS Lambda functions. Any delay was eliminated by configuring a trigger function to fire at each new upload of a product image. This immediately passes the visual asset through a pipeline that checks for the product type and proceeds with the background removal step.
After this process, a team takes control of the image and uploads it to the website. Due to minor errors in the algorithm, about 600 images out of 10.000 still need manual adjustment. They are most commonly associated with low-contrast images, clothing that is the same color as the background, and very thin straps where the shadow may be the same color as the strap.

Ongoing maintenance: Monitoring for decreased performance
The model’s performance is likely to deteriorate over time. This is why, in an ideal pipeline of production, the performance of the model should be carefully monitored, and lower IoU scores should trigger a retraining on new sets of data. Even a 6% error rate on real images could be significantly reduced with careful data set curation and adjustments.
After one and a half years of work, the deep learning algorithm now handles the majority of background removal for the e-commerce store. The model has been in production for over a year and flawlessly processes over 94% of product images without the need for manual intervention. The system has transformed the image processing workflow at Wehkamp, allowing for faster product launches and accelerating business growth.