The world around us relies heavily on routine, to the point where sometimes our own safety depends on it. This creates the need for tracking routine and providing accountability when routines are not followed.
Whether it’s completing a safety checklist before using heavy machinery, verifying that an approval process was followed, or making sure maintenance happened on time, tracking user inaction can be just as important as tracking the action itself.
For our project, we had to solve this exact type of challenge: tracking whether a required checklist was completed before our users started using their equipment. In this article, I’ll walk you through our approach, which leverages the power and convenience of AWS tools like EventBridge and Lambda.
Mission: tracking missed actions
The core of our project was ensuring that critical actions were either completed by the user of some equipment or flagged as missed by our application, so the equipment fleet manager would have a report with the performed and missed actions.
Think of it as a “pre-flight” check for trucks, forklifts, or any piece of heavy machinery that would imply a certain routine for safety measures. Missing this step could produce some serious risks.
However, there are plenty of other scenarios where tracking inaction is critical:
- Maintenance tasks: routine maintenance that must be performed regularly.
- Approval processes: a step in a workflow requiring approval that could stall the entire project, or could be wrongly approved if a certain routine is not performed.
- Health and safety compliance: ensuring safety checks are completed in a timely manner.
Each of these use cases imply tracking not only when the users do perform required action but also when they don’t. And this is where it got interesting: how do we automatically record a missed action if a user simply doesn’t do anything by the end of the day, or by the end of the allowed timeframe for that action?
We would name these routines checklists, which have a certain recurrence defined and an associated list of equipment references, and every successful action of such a checklist is a performed check, meaning that we have to determine the missed checks.
Initial approach: dynamic generation of missed checks
Before we arrived to our current solution, we started with a completely different approach. Our first idea was to keep track of user inaction based on performed action, which may initially seem counterintuitive.
The logic was to determine when user action should occur and, on each required date, verify if a recorded action exists. If no action is found, we mark this as inaction, recording a missed check to be displayed on demand in our front-end for the equipment fleet managers.
This seemed like an attractive, fast and easy solution, but it had two significant limitations. First, as the timespan that needs to be tracked and the size of the equipment fleet grows, this process becomes heavier, as we would have to iterate through more days, more checklists and more equipment. While implementing a caching mechanism might mitigate this issue, we still have the second, and most critical limitation: we were essentially generating historical data based on the checklist configuration that we have now. This means that if the recurrence changes, we will generate a completely new set of missed checks the next time the equipment fleet manager will request another report.
Solution: EventBridge Scheduler and AWS Lambda
We came up with the following plan:
- Any update of a checklist’s recurrence (including creating and removing checklists) must also update a corresponding Schedule to reflect the new recurrence.
- Each Schedule would trigger another AWS Lambda function and provide the checklist that it is invoked for as argument, at the end of every day that we expect an action for the checklist.
- For each piece of equipment that is associated with the provided checklist, check if there is a performed check recorded during the given timespan. If not, create a missed check entry in the same DynamoDB table as the performed checks.
This setup allows us to create a persistent record of both successful and missed actions, which is perfect for auditing purposes, safety enforcement and accountability. It can also be a great starting point for other features like dismissing a missed check or anything involving the missed action entity.
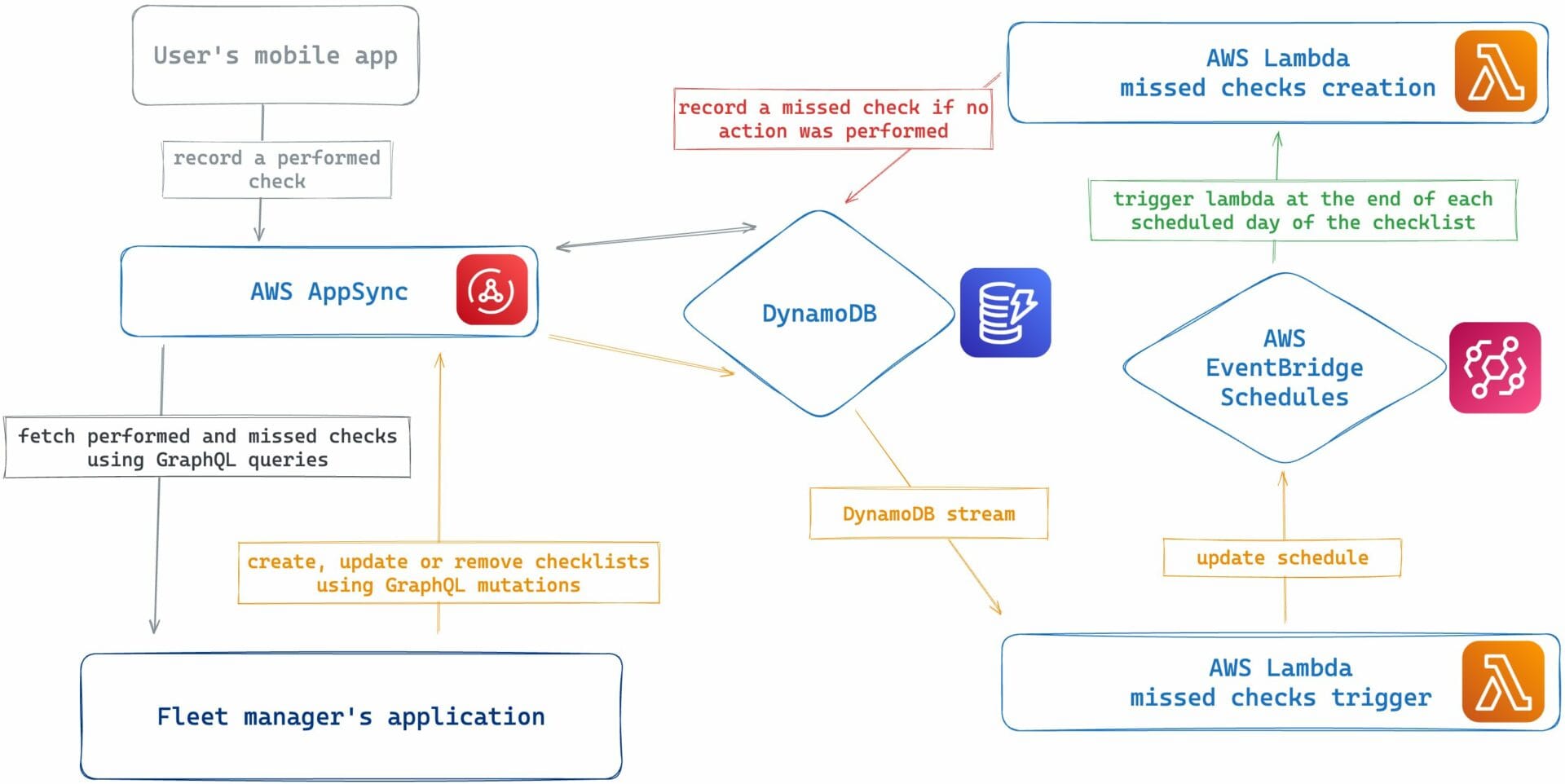
Managing schedules dynamically
The checklists themselves are managed by our application and stored inside a DynamoDB Table. Our equipment fleet managers can create, update, or remove such checklists – each checklist has its own recurrence, like “every Monday” or “the 1st of every other month”. This adds a layer of complexity since any change in a checklist’s schedule needs to be reflected on the corresponding EventBridge Schedule.
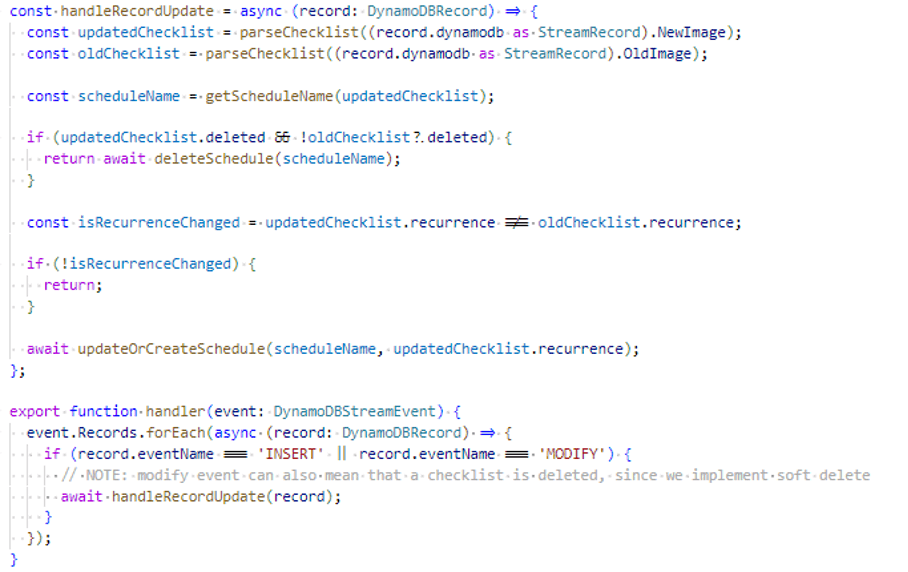
In order to handle this, we set up a “listener” AWS Lambda function, which would act upon any changes to the checklists in our DynamoDB table, leveraging DynamoDB Streams. When a recurrence is updated, the listener updates the corresponding EventBridge Schedule as well, to ensure it reflects the correct timing.
The goal here is simple: keep everything in sync so that the lambda that checks for missed events would run only when it’s supposed to.
Here is a simplified implementation of the listener lambda function.
AWS Scheduler limitations & recurrence management
The Scheduler handles recurrence using cron expressions, which can be limiting in term of flexibility. For instance, there is no simple way to say “run this every other week”. Instead, we have to set its recurrence to “every week” and add logic inside the triggered Lambda function to decide if it should act based on the frequency computed from the checklist’s recurrence rule, or skip the invocation.
To manage the recurrence of our checklists, we use RRule strings, a recurrence specification introduced by Apple. RRule is a powerful recurrence rule syntax used for describing complex recurrences, like “first Monday of every month”, or “once every three weeks on Monday and Friday”. But since EventBridge doesn’t directly understand RRule, we needed to convert these RRule strings into something the AWS infrastructure could handle, namely cron syntax.
Our “listener” function converts the recurrence rule of the checklist to a cron expression that resembles as closely as possible the RRule expression. For instance, an RRule expression representing a recurrence of every week on Monday, in the form of “RRULE:FREQ=WEEKLY;WKST=MO”, would be converted to “(59 23 ? * MON *)”, meaning every Monday at 23:59.
Fortunately, our application restricts users from adding time constraints to the recurrence, simplifying our implementation, but depending on how complex the accepted RRule recurrence is, it could be more difficult to convert it to a cron expression.
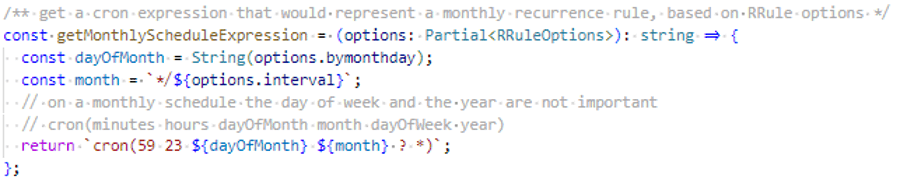
Here is a simplified example of how a conversion from monthly frequency recurrence to the equivalent cron expression could look like:
AWS Scheduler limitations & recurrence management
This scalable solution provided us with a great base for future work, by materializing the inaction and allowing us to further decorate this information. Here’s an overview:
- Checklists (routines with a predefined recurrence) are stored in a DynamoDB table, allowing us to hook into any updates of their RRule expressions.
- EventBridge schedules trigger a Lambda function at the end of each day to check for checklist completion.
- If no action was taken, the Lambda records a missed check.
- Any changes of a checklist’s recurrence triggers the listener Lambda which keeps the checklists and schedules synced. In our case, the equipment fleet managers could also enable or disable a checklist without updating the recurrence rule, which should also reflect in the schedule’s state: enabled or disabled.
For future improvements, we are thinking about breaking the link between DynamoDB streams and the “listener” Lambda and add another message queue layer, such as Amazon SQS, to allow more flexibility in handling incoming events and smoother scaling.
Another improvement opportunity could be implementing dead letter queues (messages that weren’t correctly processed) for both schedule updates and missed check creation, which would enhance monitoring and error handling throughout the entire system.
With EventBridge Scheduler and AWS Lambda we were able to provide reliable reports which are no more expensive to generate than querying information from a data-base.












