Last year, Romania’s talented data science team won Hack9, Levi9’s international hackathon competition. We sat down with Ștefan Gabriel Iftime (data scientist) and Maxim Datco (data engineer), who were part of the winning team, to gain insights into their ingenious computer vision solution that dominated the competition.
Hack9: Levi9's hackathon challenge
Hack9 brings together Levi9 employees from delivery centers across Romania, Serbia, and Ukraine to compete in developing creative solutions aligned with business needs. “A hackathon is mostly about learning new skills and applying them to client projects, but also about having fun and putting your mind to work on something different from your daily tasks,” Ștefan explained.
The 2023 challenge tasked participants with building a model capable of accurately establishing whether or not a Levi9 logo is present and locating it in various photographs. The goal was to detect logos despite real-world conditions like distortion or obstruction. “The mission was to identify the 9 from the Levi9 logo within each image. The more precise your detections, the higher your team’s score,” Ștefan outlined. Success hinged on identifying partial or blended logos that were, in some cases, nearly indistinguishable to the human eye.

Assembling the winning team
Ștefan assembled a small but mighty team to tackle the challenge, drawing on expertise in data science, data engineering, and project delivery. Team sizes ranged from three to six members, and while some groups had more manpower, Ștefan’s squad compensated with their focused expertise.
Vision model and dataset preparation
The team needed to choose a pre-trained vision model, as building one from scratch in just five days was impractical. They selected Yolo V8, a state-of-the-art model at that time, that had been pre-trained on Facebook’s COCO dataset. “It is able to detect 80 different objects inside images, even if multiple types are present in a single picture,” Ștefan detailed. Panoptic segmentation training data allows for both the recognition of objects (such as cars) as well as different instances of the same type of object (for example, knowing that there are two cars in the same image).
The hackathon organizers provided training data containing various examples with prominent Levi9 logos and challenging images where the logo blended into complex backgrounds. While a vision algorithm could achieve a high score of around 90% with this initial data, the team recognized the need to enhance the dataset.
“The training data consisted mainly of clear images where the logo was clearly visible,” Maxim explained. “However, the test data—the images where the algorithm was tasked with finding the logo—were much trickier. This meant that the training dataset also needed to cover edge cases where the logo was barely visible or distorted.”

Enlarging the training data: The winning strategy
Their first order of business was expanding and enhancing the initial training data. “We tried to grow our dataset with examples mirroring the test set,” Maxim said. By adding more partially obscured or distorted logos, they prepared the model for the imperfect real-world images it would encounter in the test data set. They rotated, resized, blurred images, changed the contrast, and cut out parts of the logo. “We wanted the algorithm to learn from as much information as possible, as the initial training data did not truly resemble the evaluation dataset,” Ștefan added.
“I think this was what set us apart from the others,” Ștefan emphasized.

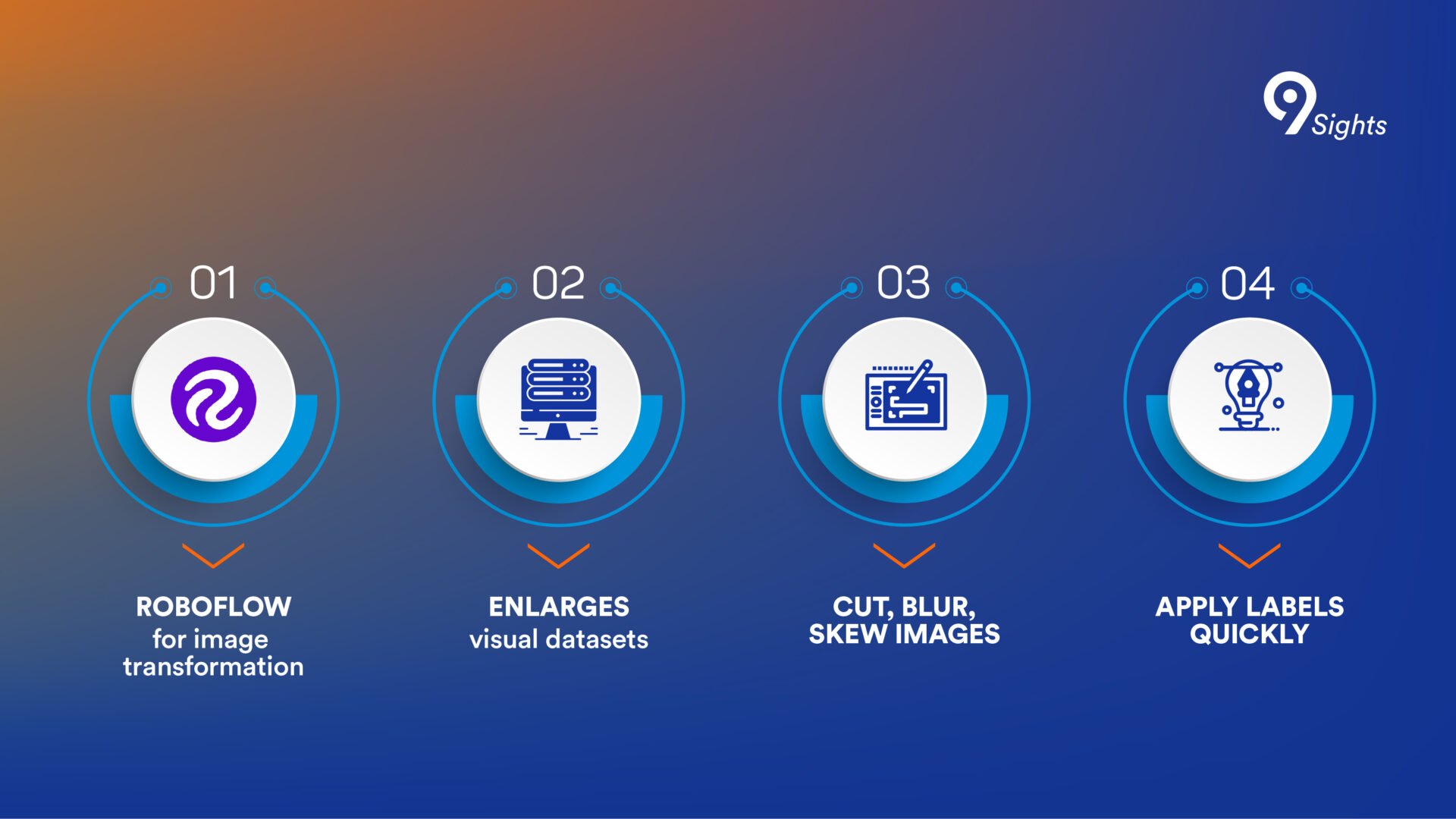
Secret ally: Roboflow
To quickly upgrade the dataset, the team utilized a tool called RoboFlow, which Maxim dubbed the “revelation of the hackathon.” “It allows users to very easily extend your dataset and apply more transformations to images. It was very easy to transform and label data.”
With this ace up their sleeve, the team more than tripled the dimension of the provided dataset. In essence, their computer model had access to better teachers.
The 80-20 rule in data science
Both Ștefan and Maxim agreed that data preparation was the most time-consuming process. However, they also credited this process for the success of their model.
“We applied the 80-20 rule in data science,” Ștefan explained. 80% of the time was spent doing only the initial part of any computer vision project: the image preparation, while 20% was used to train, optimize and evaluate the model. “Without quality, clean data, even the most advanced model can’t deliver accurate results,” Maxim emphasized as well.

Model refinement
With an expanded dataset, the team began training models and fine-tuning initial versions that underperformed. Competitors on the hackathon platform could view real-time rankings as teams submitted their models. When a Serbian squad briefly outperformed them, it instilled a competitive drive to refine their solution further and secure the win. “It made us much more competitive to improve our solution and secure the victory,” Ștefan said.
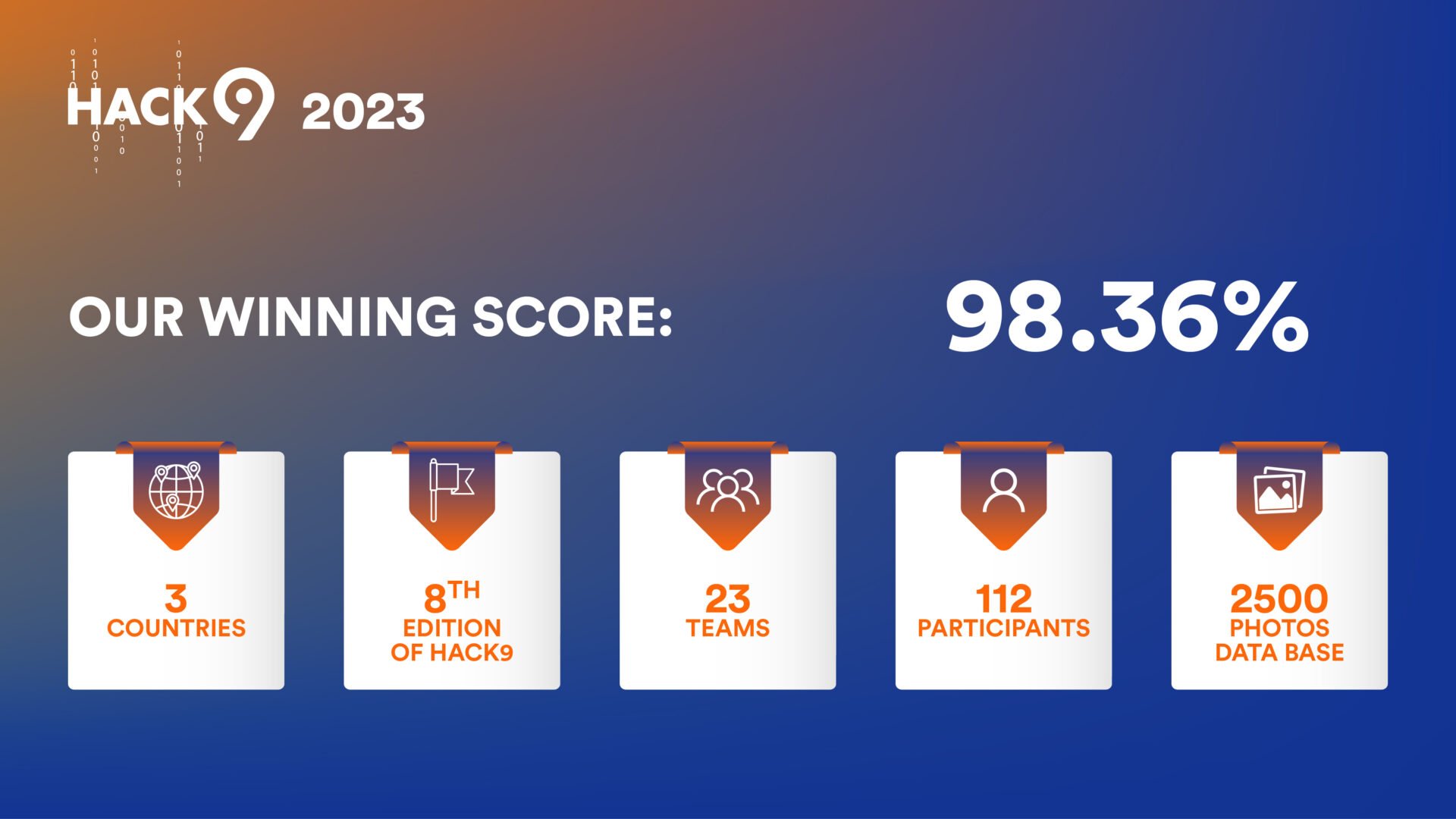
The winning score: 98.36%
After several iterations, the Romanian team achieved an impressive 98.363% accuracy—a new high score. Their submission of this top result effectively secured victory with plenty of time to spare, making them unbeatable for two more days. The entire Romanian office celebrated with beers and an outdoor grill.
Building expertise for client value
While the specific logo detection model doesn’t directly translate to a current client business, Ștefan believes the task in itself holds immense value for real-world computer vision projects, such as copyright issues, brand recognition, or disease detection in medical imagery.
Being ready for the problems of tomorrow is the whole point of Hack9. “It’s all about gaining hands-on experience,” Ștefan and Maxim concluded. Understanding how to train computer vision models, correct errors, and improve performance through data enhancement is vital knowledge for future tasks where advanced image recognition is needed.