
Back in 2006 when the phrase “Data is the new oil” was stated for the first time, it teased a possibility of a new trend which might be the next big thing on the horizon. Yet, probably no one at the time anticipated the role data would play in the near future and the ways it would affect the technology stack, accompanied by a plethora of architectural principles and a variety of new job opportunities.
Today we are witnessing the rise of industry in which the most profitable enterprises are those which own the data and are directly or indirectly generating profits from it. Advanced analytics, predictions and reporting are driving the implementation of data-driven business model. This is a very dynamic area that has witnessed many trends and architectures designed to enable data collection, processing and storage of large amounts of data while meeting the needs of scalability, security, automation and complying with legal regulations.
Although it is difficult to find an industry in which this model is not applicable, the digital marketing industry stands out as perhaps the most dominant one primarily because of real time bidding and smart targeting. Other domains that rely heavily on data are market analysis in regular sales chains, logistics in various forms, and with the growing popularity of the IoT concept smart cities, the automotive industry, transport, and many other domains that are using data to optimize processes.
In this article, we will touch upon some of the technologies and architectures that make these things possible in practice and share the experiences, challenges, and dilemmas we encountered through various projects, primarily emphasizing Data Lake architecture on the Cloud platforms as one of the most popular at the moment.
When talking about data-lake architecture, it implies designing a system that collects and stores data from many different sources in a way that enables cheap and scalable storage of structured and partially structured data with the possibility of performing the transformation processes aiming to create the necessary data projections. Projection is the result of a process that transforms raw data, enriches it with data from other sources or performs aggregations and finally stores it so that the data structure and the format itself are clearly defined and usable. Depending on the case, technology stack builds upon two main principles, data streaming and batch data processing, quite often combining both approaches. Although there are cases when the near-real-time approach has its place, when it comes to data lake architecture, the ‘batch’ data processing usually plays more significant role.
Designing a data lake: Cloud or on-prem system?
There are many parameters that play an important role when it comes to designing a data-lake system. If we look at some of the most common challenges and problems in implementation, it is inevitable that we will come across things like scalability, cost optimization and investment justification, the richness of the ecosystem of tools that are suitable for the given problems and the possibility of their integration, as well as issues of availability (SLA), reliability, ease of maintenance, speed of development, legal regulations and data security.
Bearing this in mind, perhaps the first question that arises is whether developing the system on the on-premises infrastructure or on one of the Cloud platforms better fits the case.
The enormous number of migrations of existing systems to one of the Cloud platforms, as well as the large number of projects that start as Cloud solutions is no coincidence. The following chapters will dive into the common challenges and things that should be considered when designing a data lake while point out some of the advantages of Cloud platforms.
Efficiency and scalability
Assessment of the current needs and prediction of potential growth can be a challenging task. When talking about on-prem system, it is necessary to assess the current needs as well as the potential growth in the upcoming period in order to put together a business justification for securing the funds.
On the other hand, Cloud Platforms usually charge for services based on used or reserved processing power and used storage, and with this billing model, they enable quick start of the journey towards an MVP solutions. As the complexity of requirements increases as well as the amount of data, the Cloud platform system can be easily scaled up. Storing data in the form of blobs is usually very cheap and practically unlimited. Database servers can be scaled as needed with the allocation of stronger instances, while processing power in the form of code packaged in containers or distributed systems that are terminated after the work is done is charged according to the used processing power and other resources. Tools like AWS Glue, Google DataFlow, AWS Cloud Functions etc. are just some of the options that offer those capabilities.
Data Catalog and service integration
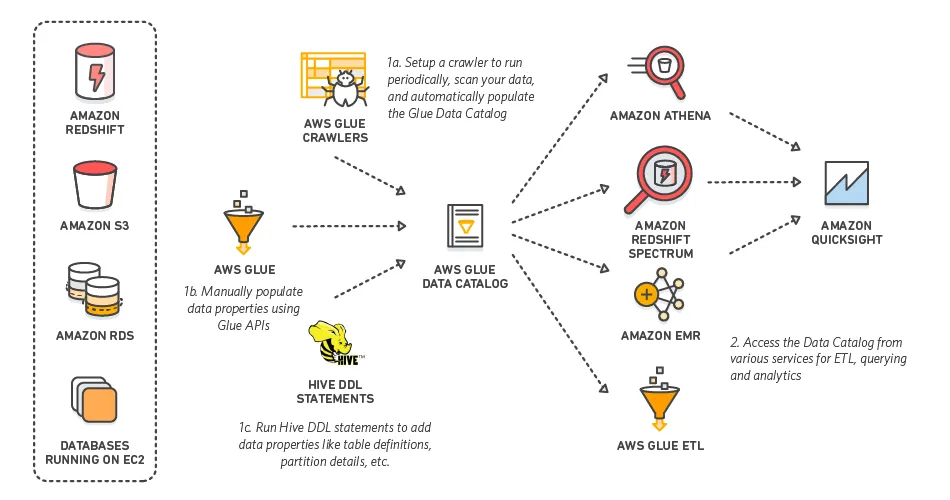
Storing structured data in one of the formats such as AVRO or Parquet with an adequate hierarchy of folders (or paths) that enable efficient partitioning is very popular and, by many criteria, efficient and cost-effective way of storing data. Within the AWS platform, the tool that enables usage of data stored in files giving them semantics and making them discoverable and suitable for querying is called Glue Data Catalog.
The idea behind the Data Catalog is to create a unique interface for interaction with data regardless of whether the entity in the Catalog is stored in a database, file on S3 or some other type of storage. This approach enables outstanding integration possibilities between different components within the AWS platform.
Let’s take for example the fact that AWS Glue jobs, which are one of the ETL tools offered by platform, can manipulate data from different databases and combine it with data from S3. The same data can be queried via Athena SQL-like queries directly, and in cases when it is needed, it is even possible to create a temporary Redshift cluster that will perform some heavy processing after which it can be terminated. All of that can be orchestrated with some kind of orchestration tool such as Step Functions and automated with some of the “infrastructure as a code” services like CDK.
The existence of Data Catalog as well as direct integration between components such as various types of consumer and producer tools for message queues, process orchestration tools and the possibility of implementing event driven architecture leave many possibilities for designing complex architectures. That kind of freedom is difficult to achieve in the on-prem systems.
Reliability, maintenance, and security
There is a huge variety of tools and frameworks that play a particular role and represent a vital part of the data pipelines and overall data architecture.
To mention a few of them, let’s take for example a data streaming platform Apache Kafka or data storage and processing framework Hadoop with all the tooling within the ecosystem that they have. Now let’s imagine the maintenance of Kafka and Hadoop clusters, the necessary monitoring of the vital components of the machines, such as:
- Free disk space
- Processor and memory allocation
- Sharing of hardware resources with other applications (shared & noisy hardware) and users
- Failure of one node in the cluster and redistribution of the topics to another
- In a slightly more extreme case, the termination of the master node
Let’s consider upgrading the version on the system that is in use or expanding the system by adding physical machines or disks. These are some of the challenges teams face when working on on-prem systems. Of course, those systems undeniably have their place, primarily in organizations that want their data not to leave the organization due to regulations or in organizations that already purchased hardware. Many big players have their own hardware, and in those situations development on that hardware is usually a better option, but in other situations when this is not the case, it is hard to ignore the advantages that cloud solutions bring.
Some of the benefits that stand out are reliability in the form of responsiveness guaranteed by the Cloud provider itself through its SLA, replication between Availability Zones in case of incidents, maintenance of versions and libraries in services, scaling when needed, integration and optimization as well as security itself, which is implemented on many levels starting from the network, through encryption up to the granular access control policies.
Cost optimization
We talked about integration, security and ease of use, but in all of that I would like to specifically pay attention to the importance of understanding the service billing model, and through just one of many examples show how some decisions drastically affect the costs.
Let’s take encryption as an example. File encryption in a Data Lake is a very important layer of data protection and access control. AWS offers several options for choosing the type of key through its KMS service so that it is possible to find the optimal ratio of control over the encryption key and price depending on the needs of the system. Decryption of files happens every time user queries them. Imagine teams of data analysts regularly querying large amounts of data directly from files using tools like AWS Athena or scheduled queries that run regularly. As it is a centralized system that will be used by many teams and other systems, and the intensity of querying is very high, the optimal choice of the type of key plays an important role in optimizing the costs of decryption and the total costs of the entire Data Lake system.
To sum things up, yes, it does sound attractive but beware of the costs! Think about what security level do you really need. Difference between SSE-KMS and SSE-S3 can be $1.000+.
AWS, GCP, or Azure? Similar concepts, different skin
In the previous examples the primary focus was on AWS tools, but not surprisingly, similar possibilities are offered by other Cloud platforms as well.
While working on different Cloud Platforms, one cannot but notice a repeating patterns and similarities. Most of the services designed for a specific type of problem (storage, serverless execution, orchestration, message queue and so on) can be found on all platforms. In addition, some of the tools that these platforms offer come from the open-source world. They are optimized to fit within the platform and there is a layer for integration with other components on top of them. In that context, if we look closely at the implementation of AWS Glue Jobs, we find the well-known Apache Spark, which is not surprising considering that the very syntax used to define Glue jobs is actually PySpark under the hood (for those who decide to go with Python). The apparently new concept of DynamicFrame is nothing but a DataFrame just additionally optimized and with interfaces for easier integration with other services. If we look at the GCP rival named DataFlow behind the curtain we find nothing else but Apache Beam, which is again more than obvious considering the syntax for defining jobs.
Examples are many, however the point is that many of the tools that the platforms offer are based on open source tools that have been around for a long time. Implementations in the Cloud environment are based on some slightly more traditional concepts, but Cloud platforms make the job easier as they reduce the need to maintain physical machines, guaranteeing reliability, security, scaling, and offer significantly simpler ways of integrating and orchestrating processes.
Now, let’s compare some of the frequently used services and tools that are part of a certain platform which are intended for the same kind of problems. We will take into account the three currently most popular Cloud platforms: AWS, GCP, and Azure.
Code execution in the form of small tasks with fast response time and limited resources is something that undeniably fits into many scenarios in data lake implementations and in many others. All observed platforms offer such a service. As part of the AWS platform, we are talking about the AWS Lambda service, GCP offers us this possibility through the Google Cloud Functions service, while on Azure it is called Azure Functions. All services are event driven, serverless with minimal differences and most of them are related to statistics like maximum resource allocation and execution time.
In addition to standard SQL and document-oriented databases, a Data Warehouse intended for analytical queries is also an inevitable tool offered by every platform. The symbiosis of such databases and data lakes will be mentioned in the following sections, and the tools offered by the platforms are Amazon Redshift, Google Big Query and Azure Synapse Analytics. The main differences between these services are in the way of resource instantiation, the way of scaling, as well as the mechanisms for optimizing query costs (sort key, partitioning…).
Batch processing of large amounts of data, as an extremely important segment in the design of the data lake is supported through services such as AWS Glue, Google Data Flow and Data Prep, as well as a very rich set of Azure tools, including Azure Data Factory.
Up until now we were dealing with technologies and environments suitable for data lake development. Now, let’s have a look at some types of expansion of that architecture and check out some trends that came out as a response to challenges of both a technological and organizational nature.
Data lake and lakehouse
Although Cloud Platforms offer many possibilities when it comes to querying data directly from Cloud Storage, a slightly more traditional and very common type of data projections is storing data in OLAP databases, i.e. Data Warehouse. They are much more suitable for analytical querying bearing in mind that they have built-in mechanisms for optimizing the speed and cost of queries through partitioning, and the fact that they are columnar databases lowering the amount of data scanned in a query. Many visualization tools or tools for advanced analytics offer simple integration with such databases. Possibility of data modeling in a star or snowflake schema and transferring part of the logic to stored procedures make them a very logical choice in many situations. This symbiosis between the storage of original data in the form of blobs (data lake) and projection in the OLAP databases (data warehouse) is called a lakehouse architecture.
This approach covers a variety of use cases. For some of the most common ones, let’s take for reference the tools offered by AWS. In cases where it is necessary to perform quick ad-hoc queries on the data in the Data Lake, AWS Athena is a perfect fit, while in the case of complex analytical operations and reports, choosing a DWH solution, specifically AWS Redshift, usually makes more sense.
Data lake or data mesh: Technological or organizational dilemma?
Being a centralized system, as by its core nature data lake is, brings many benefits but has it’s downside as well. Let’s for a moment think about scalability but not in terms of computational power but rather a scalability in terms of different domains that a single data lake can integrate with. There is also wide variety of business domains that data lake team probably don’t have experience with or a full understanding of how they operate and integration with all sorts of 3rd party systems, many of which can be closely encapsulated within it’s own ecosystem. Building, maintaining and monitoring such system is a though challenge and the only logical answer in this scenario is decentralization.
The concept of data mesh architecture has been introduced with the main idea being redistribution of responsibility at the corporate level, in which the central data team is responsible for providing a system and a clearly defined way of integration with it, while the delivery of data and final use is the responsibility of the teams in whose domain the data is, i.e. teams that own that data. Looking at things from this perspective, the difference between these two approaches is primarily of an organizational nature, while the stack of technology used in both approaches is quite similar.
Data lake layers
When talking about layers in a data lake, it usually closely relates to a different segments of the architecture like data ingestion layer, data processing layer, insight gathering layer, etc. Now let’s put things in slightly different perspective and talk about layers as different stages of data itself in a data processing pipeline and the phases of data transformations that are usable for certain groups of people but highly sensitive to be exposed to others.
Layering of data lakes serves multiple purposes but the most common one is related to data sensitivity regulations and privacy. Usually, right after the ingestion, data is stored in a raw format without any transformations and cleansing. This layer is never exposed to the users and serves a purpose of backup and a source for building data projections. On top of raw data, usually as soon as file arrives, the first transformations are being applied resulting in a more structured files, stored in a different location and this is where things become interesting. Up from there data goes through multiple transformations and each of them results in a layer that can serve a different purpose. For example, one data projection can serve as a fully anonymized projection that is perfectly suitable even for external usage and usage by different teams while some other projections can contain more sensitive data for internal usage. Some of the layers can incorporate a set of transformations that can ease the querying later on or store data using different partitioning patterns and even formats.
Another common one is decoupling of the teams and groups so they can build their own solutions on top of their own layer without affecting any other users. They can rely on one of the parent layers as a single source of truth and use it as a backbone for building a completely custom-tailored solution for a specific group of users or completely separate client incorporating the transformation rules, security requirements and access control completely separately from the other users.
Solution as a service: Databricks
What at some point might be a “next big thing” in the industry sooner or later becomes an industry standard which usually attracts the attention of large development teams or groups of enthusiasts with the goal of developing a solution that encapsulates an entire ecosystem of tools and offering it as platform or service. Some examples would certainly be the Confluent platform around the Apache Kafka ecosystem and Cloudera around Hadoop technologies.
Since our topic is data lake, in this section we will focus on Databricks — a service that offers many elements of a data lake and data warehouse as a managed solution and represents a kind of example of how a data lake that additionally includes many advanced tools for analytics could look like if it is offered as a service.
Databricks combines data lake and data warehouse solutions, offers options for team collaboration, and goes one step further by offering tools for BI and machine learning. It also covers many standard use cases and scenarios that are based on established good practices, primarily talking about how to store data, data querying, data catalog and system monitoring. When choosing between custom tailored solutions and the approach in which we completely rely on the capabilities of the SaaS platform there are many factors, few of them being the billing model, the specifics of the system that is being developed, and the size and structure of the team. It is certain that such services have their place and are worth considering during the initial design of the solution and currently it is an example that will undeniably be followed by many and strive to improve even further.
Conclusion
This article briefly covered data lake as one of the popular approaches when it comes to creating a backbone for data-driven business model. We saw what is the primary role that it serves and how it can be additionally expanded so it covers a wide variety of use cases.
We considered the advantages of developing a data lake in the Cloud and had a glimpse into what the near future brings in the form of fully managed solutions that encapsulate the entire ecosystem of tools.
We also touched upon the similarities between different cloud providers and the core concepts that were used as a solid base for building specific tools and services and how the understanding of the core concepts will make this journey much easier, maybe even up to the point where cloud-agnostic development will not be that much of a challenge and even become a standard.
As stated at the very beginning, this field is not a new thing, but it certainly is dynamic. At this moment there are many good practices that have proven to be effective and many architectures that gave an answer to wide variety of challenges. Also, bearing in mind the growth trend of the generated and stored data, one thing is certain – new challenges and new interesting technologies are yet to come.









